2023. 1. 12. 17:25ㆍPython
파이썬 easyocr 이미지 문자 인식
[리원아빠] 파이썬 tesseract pytesseract 이미지 문자 인식
파이썬 tesseract pytesseract 이미지 문자 인식하기 파이썬으로 무엇을 또 만들어볼 수 있을까? 고민을하다가 우연히 알게된 pytesseract. pytesseract는 tesseract를 파이썬에서 사용할 수 있도록 일종의 다리
liwonfather.tistory.com
바로 이전 포스팅에서 tesseract를 이용해 이미지 안의
문자를 인식하는 방법에 대한 포스팅을 했었다.
만들고자 하는 프로그램이 있어 추가로 테스트 및 학습을 하는 도중
보다 더 손쉽고 인식률이 높은 방법을 찾아 바로 이어 포스팅한다.
pip install easyocr파이썬에서는 easyocr이라는 tesseract에 버금가는 OCR 기능을 모듈로 제공한다.
간단하게 pip를 통해 해당 모듈을 설치할 수 있다.
import easyocr
import cv2
file = r"C:\Users\root\Desktop\sample.png"
reader = easyocr.Reader(['ko', 'en'], gpu=False)
img = cv2.imread(file)
text = reader.readtext(img, detail=0)
print(text)sample.png 파일은 이전 포스팅에서 사용한 naver 홈페이지의 로그인 버튼을 캡쳐한 이미지다.
easyorc은 reader라는 오브젝트를 생성 후
해당 오브젝트의 readtext 함수에 이미지와 옵션을 전달하는 방식이다.
먼저, reader 오브젝트를 생성할 때는 추출할 언어를 선택할 수 있고
CPU 연산 대신 GPU 연산을 선택할 수 있다.
GPU 연산이 CPU 연산보다 빠르다고 하나 작성자의 PC는 오래되어서 그런지 사용되지 않았다.
readtext 함수에는 읽어들이 이미지와 옵션을 전달할 수 있는데
detail=0 옵션은 단순히 결과값만 추출하고 싶을 때 사용하는 옵션이다.
detail=0 옵션을 생략하면 이미지가 추출된 영역의 좌표와 크기까지 같이 출력된다.
추가로 allowlist라는 옵션도 눈여결볼만 한데 해당 옵션은 추출될 수 있는 가지수를 지정하는 옵션이다.
예를 들어 숫자만 인식한다고 하면 allowlist="0123456789" 로 전달하면 된다.

tesseract와 마찬가지로 간단한 sample.png 파일은 손쉽게 인식이 된다.
다만 tesseract와 비교하면 수행속도가 상당히 느린편이다.
tesseract는 0.29430초, easyocr은 2.39845초가 소요됐다. (대략 10배정도 차이난다)
그럼에도 불구하고 왜 굳이 easyocr을 언급했을까?
그건 바로 인식률때문이다.
위의 예제처럼 아주 간단한 이미지는 tesseract를 사용하는게 맞다.
그렇지만 이미지가 조금이라도 복잡하다면 이야기는 달라진다.
위 이미지들은 작성자가 머신러닝 관련 포스팅을 위해 사용한 샘플 이미지들이다.
잠깐 길이 옆으로 새긴 하지만 관심있다면 아래 포스팅을 확인하자.
[파이썬] 머신런닝을 이용한 자동방지 문자 캡챠 뚫어보기
새로운 프로그램을 만들다가 자동예약을 방지하는 일명 캡챠(Captcha)를 뚫어야 하는 상황이 발생했다. 검색을 해보니 캡챠를 뚫기 위해서 흔히 OCR이나 머신런닝을 사용하고 있었고 나는 머신런
gam860720.tistory.com
다시 본론으로 돌아와 위의 이미지들을 tesseract와 easyocr에서 추출해보자.
### tesseract ###
import pytesseract
import cv2
import os
dir = r"C:\Users\root\Desktop\sample\\"
for i in os.listdir(dir):
img = cv2.imread(dir+i)
result = pytesseract.image_to_string(img, config="--psm 6 -c tessedit_char_whitelist=0123456789")
print(i +" => " +result)
### easyorc ###
import easyocr
import os
import cv2
dir = r"C:\Users\root\Desktop\sample\\"
reader = easyocr.Reader(['ko'], gpu=False)
for i in os.listdir(dir):
j = 0
img = cv2.imread(dir+i)
text = reader.readtext(img, detail=0, allowlist="0123456789")
print(i +" => " +text[j])
j += 1위 코드는 tesseract를 이용해 숫자를 추출하는 코드.
아래 코드는 easyocr을 이용해 숫자를 추출하는 코드이다.
두 가지 방식 모두 구글링을 통해 숫자만 추출하는 옵션을 주었다.

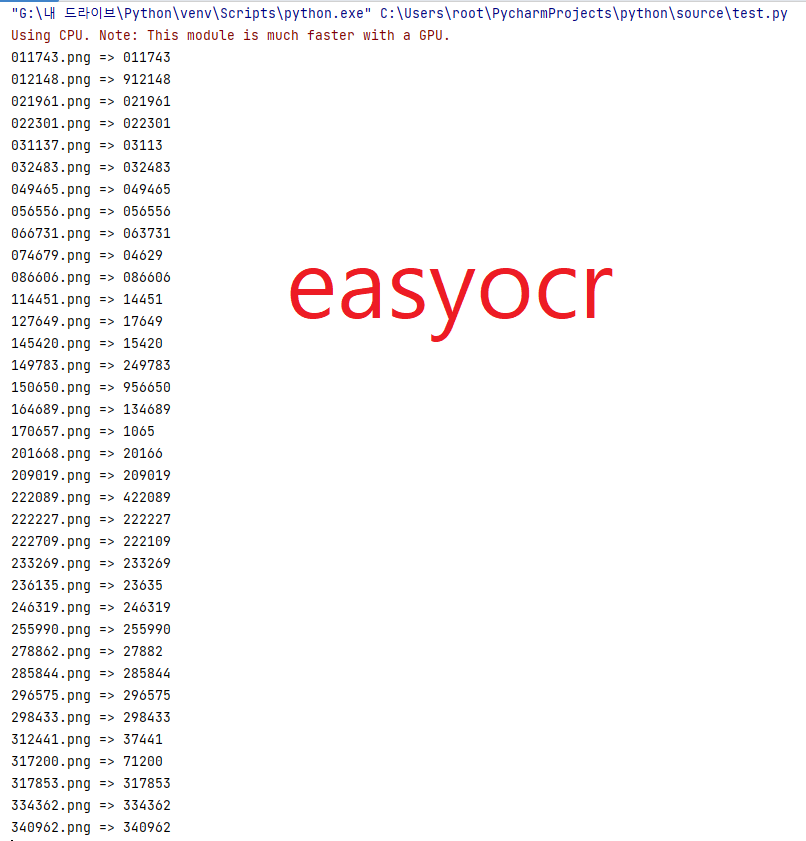
인식률의 차이가 보이는가?
opencv를 이용해 이미지를 보다 추출이 잘되는 방향으로 변환을 하면 모르겠다.
다만 아주 간단하게 사용하고자 할 땐 easyorc의 인식률이 눈에 띄게 좋은것 같다.
그럼 끝.
PS.테스트를 하고자 하는 분들은 본문의 머신런닝 링크를 타고 들어가면 샘플 이미지를 다운 받을 수 있다.
'Python' 카테고리의 다른 글
| [리원아빠] 파이썬 뉴스 기사 텍스트 글 요약하기 (0) | 2023.01.26 |
|---|---|
| [리원아빠] 파이썬 numba 모듈 패키지 속도 향상 개선 (1) | 2023.01.16 |
| [리원아빠] 파이썬 tesseract pytesseract 이미지 문자 인식 (2) | 2023.01.12 |
| [리원아빠] 파이썬 화면에서 특정 영역 찾기 (0) | 2023.01.11 |
| [리원아빠] 파이썬 GUI 환경 쓰레드 적용 응답없음 멈춤현상 해결책 (3) | 2023.01.10 |